训练自定义检测器模型
使用 Roboflow、Google Colab 和您自己的数据集,您可以快速为 Limelight 训练自定义检测器模型。
以下是您需要执行的步骤概述:
- 收集并标注感兴趣对象的图像。
- 在此上下文中,"标注"是指在感兴趣对象周围绘制边界框的过程。所有这些都可以在 Roboflow 的网页界面中完成。
- 或者,您可以从 Roboflow Universe 选择公共数据集
- 将标注的数据集导出为 .tfrecord,上传到 Google Drive,并使用我们免费的训练 Notebook 配合 Google Colab。
- Google Colab 允许您免费使用云端强大的 GPU 训练神经网络。
教程:
1. 数据集
Limelight 训练 Notebook 需要一个压缩的 .tfrecord 数据集。Roboflow 可以一键导出 .tfrecord 压缩包。
您可以使用 Roboflow 构建自己的数据集,或浏览 Roboflow Universe 获取预标注的数据集。
如果您选择构建自己的数据集,请阅读以下内容:
-
您应该最大化数据集的多样性。数据集的多样性应该超过 Limelight 部署后将看到的内容的多样性。
-
数据集的质量和准确性极其重要。确保您的边界框准确并遵循统一的约定。 例如,部分被遮挡对象的边界框应该只捕获对象的可见部分。
-
类别标签使用全小写字母
-
尽量减少类别标签的数量。
-
利用 Roboflow 的数据增强功能,但确保它们合理。例如,如果您正在检测红色和蓝色球,请确保在增强数据集中不要反转或大幅修改色调。
标注或找到数据集后,使用 Roboflow 的"Download Dataset"按钮将其导出为 Tensorflow TFRecord。将此压缩包上传到您的 Google Drive。
2. 训练模型
要训练您的自定义检测器,请使用 Limelight Detector Training Notebook 启动 Google Colab 会话。
该 Notebook 不需要任何代码更改。按照以下步骤训练您的模型:
第 1 节
- 展开第一节,点击前三个代码块左上角的播放按钮。最后的"testing"代码块可以跳过以节省时间。
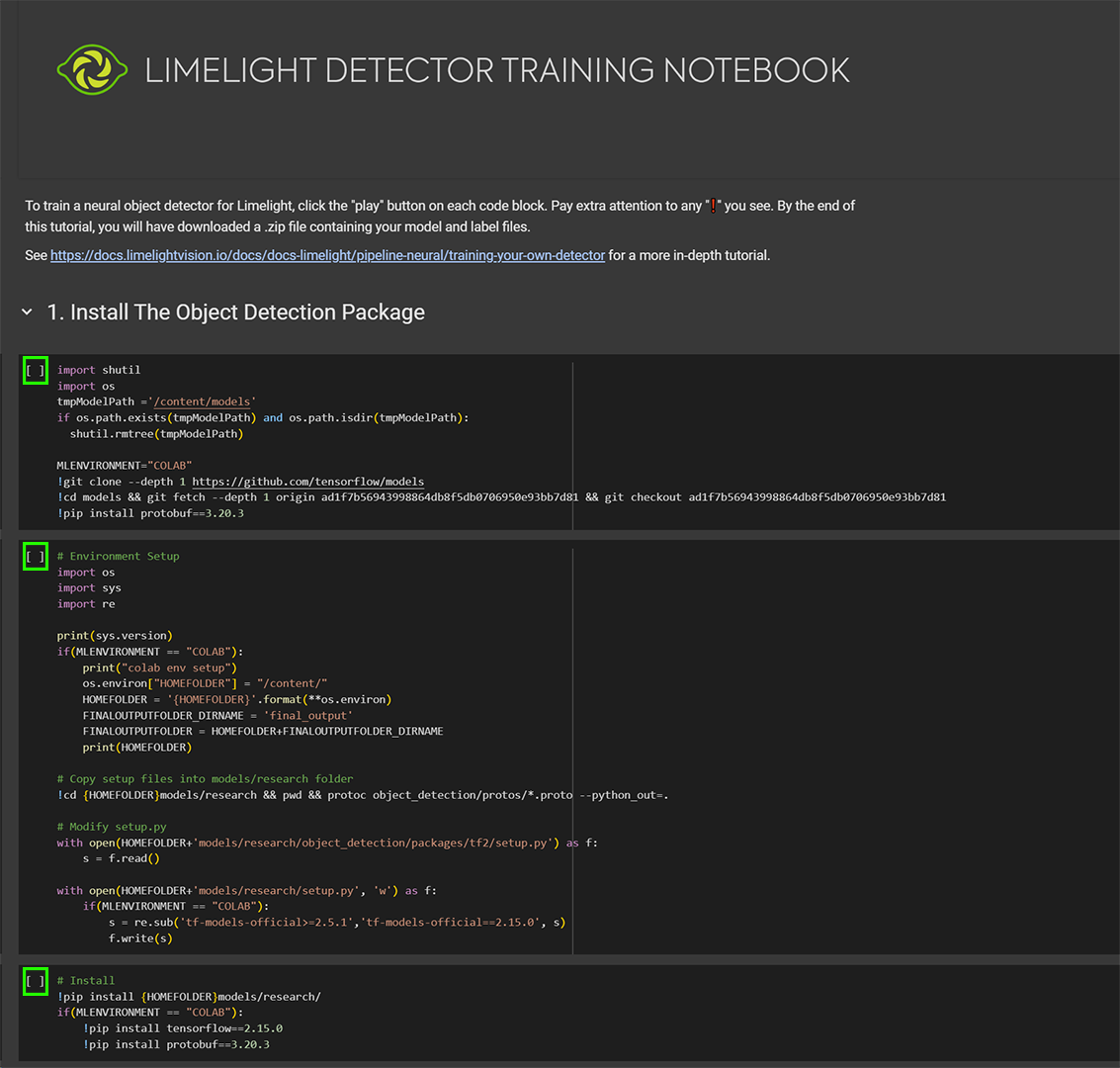
- 如果您看到重启按钮,请忽略它。

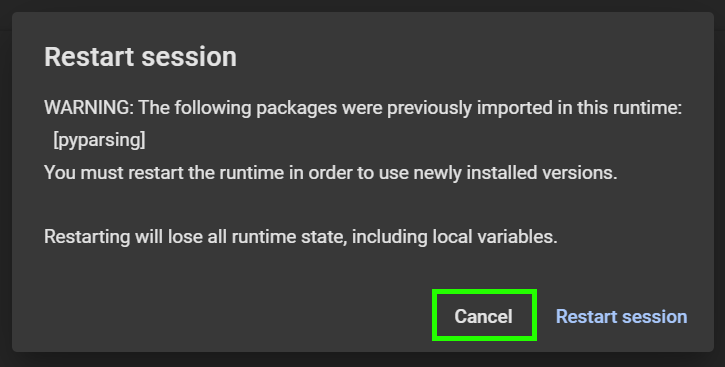
- 如果您看到这样的窗口,请点击"Cancel"
第 1.1 节
- 展开该节,运行第一个代码块,然后输入您的 tfrecord.zip 文件的 Google Drive 链接。确保您的 tfrecord.zip 在 Google Drive 中设置为"知道链接的任何人"可访问
第 2 节
- 运行两个代码块来解压和解析 tfrecord.zip
第 3 节
- 运行第 3 节中的所有代码块以准备训练
第 4 节
-
运行第 4 节中的所有代码块以开始训练。
-
在训练脚本运行时,您可以刷新文件面板和 tensorboard 来监控进度。每 2000 步会在"training_progress"文件夹中出现一个新的检查点。
-
虽然训练会在 40000 步时自动停止,但您可以随时使用本节最后一个代码块中的停止按钮来停止它。只要有可用的检查点,您就可以继续进行量化和编译。
第 5-7 节
- 运行第 5 节中的所有代码块以生成标签文件并将模型转换为兼容的 FlatBuffer 格式
- 运行第 6 节中的所有代码块以将模型量化为 INT8 / 8位推理。
- 运行第 7 节中的所有代码块以为 Google Coral 和 Limelight 准备模型。最后一个代码块需要一些时间,它会将训练好的模型下载为 .zip 文件。
上传到 Limelight
- 解压来自 Colab 会话的压缩包。
- FTC 团队 - 如果您有 Limelight3A,请上传 8bit tflite 模型和 labels.txt。您需要将运行时引擎从"coral"更改为"cpu"
- FRC 团队 - 如果您有 Google Coral,请将 limelight_neural_detector_coral.tflite 和 labels.txt 文件上传到您的 Limelight。