カスタム検出モデルのトレーニング
Roboflow、Google Colab、そして独自のデータセットを使用することで、Limelight用のカスタム検出モデルを素早くトレーニングできます。
以下は必要な手順の概要です:
- 対象物の画像を収集し、アノテーションを行う
- ここでの「アノテーション」とは、対象物の周りにバウンディングボックスを描画するプロセスです。これらはすべてRoboflowのWebインターフェース内で行えます。
- または、Roboflow Universeから公開データセットを選択することもできます
- アノテーション済みデータセットを.tfrecord形式でエクスポートし、Google Driveにアップロードして、Google Colabで無料のトレーニングNotebookを使用します。
- Google Colabを使用すると、クラウド上の強力なGPUを無料で使用してニューラルネットワークをトレーニングできます。
チュートリアル:
1. データセット
Limelight Training Notebookは、zip圧縮された.tfrecordデータセットを必要とします。Roboflowはワンクリックで.tfrecordアーカイブをエクスポートできます。
Roboflowで独自のデータセットを構築するか、Roboflow Universeでアノテーション済みデータセットを探すことができます。
独自のデータセットを構築する場合は、以下をお読みください:
-
データセットの多様性を最大化してください。データセットの多様性は、Limelightが実際に展開された後に見るものの多様性を超えている必要があります。
-
データセットの品質と精度は非常に重要です。バウンディングボックスが正確で、一貫した規則に従っていることを確認してください。 例えば、部分的に隠れた物体のバウンディングボックスは、物体の見える部分のみを捉えるべきです。
-
クラスラベルにはすべ�て小文字を使用してください
-
クラスラベルの数を最小限に抑えてください
-
Roboflowの拡張機能を活用しますが、それらが適切であることを確認してください。例えば、赤と青のボールを検出する場合、拡張データセットで色相を反転させたり大幅に変更したりしないようにしてください。
データセットのラベル付けまたは取得が完了したら、Roboflowの「Download Dataset」ボタンを使用してTensorflow TFRecord形式でエクスポートします。このアーカイブをGoogle Driveにアップロードしてください。
2. モデルのトレーニング
カスタム検出器をトレーニングするには、Limelight Detector Training NotebookでGoogle Colabセッションを開始します。
このNotebookはコードの変更を必要としません。以下の手順に従ってモデルをトレーニングしてください:
セクション1
- 最初のセクションを展開し、最初の3つのコードブロックそれぞれの左上隅にある再生ボタンをクリックします。最後の「testing」コードブロックは時間節約のためスキップできます。
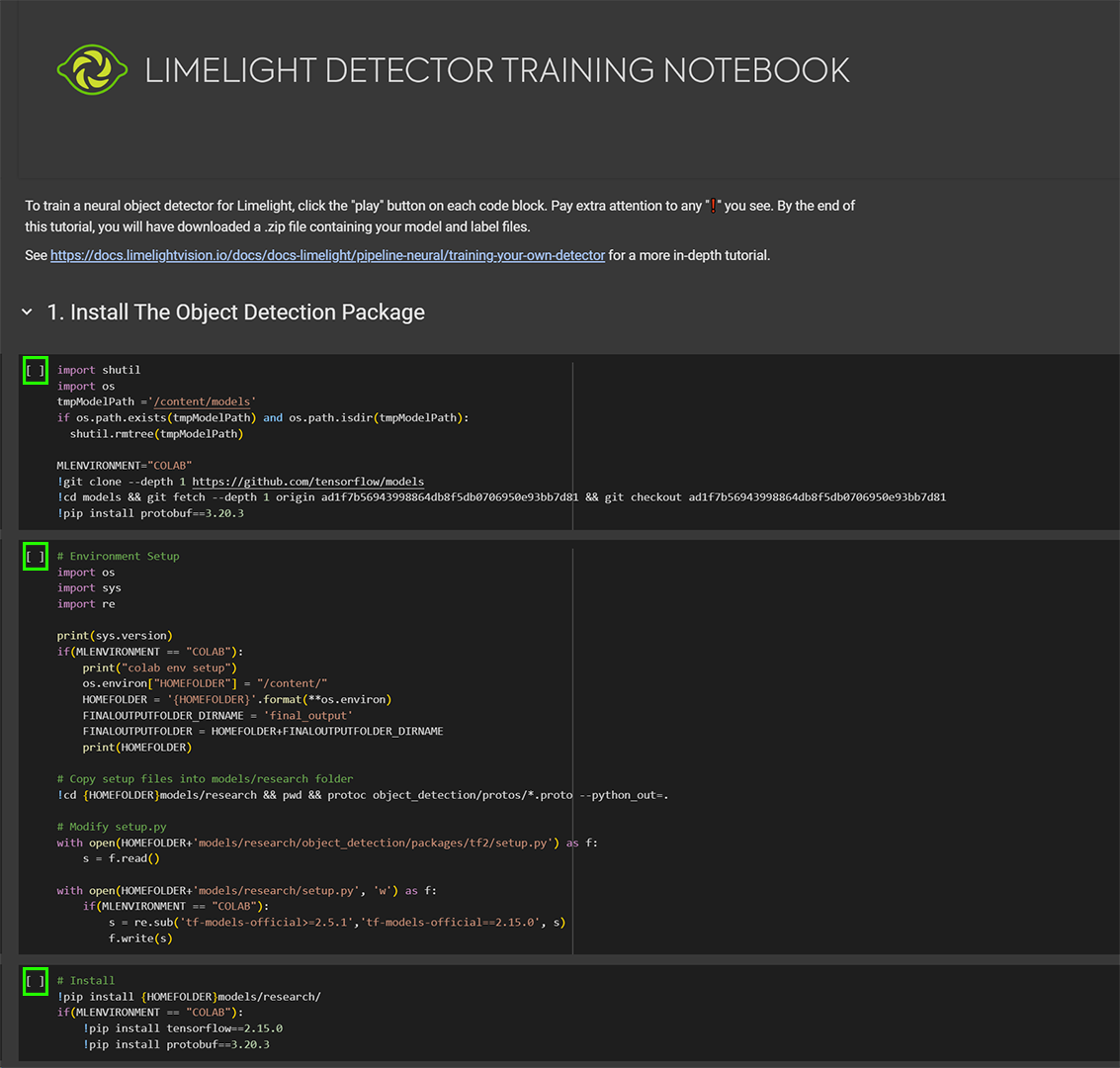
- 再起動ボタンが表示された場合は、無視してください。

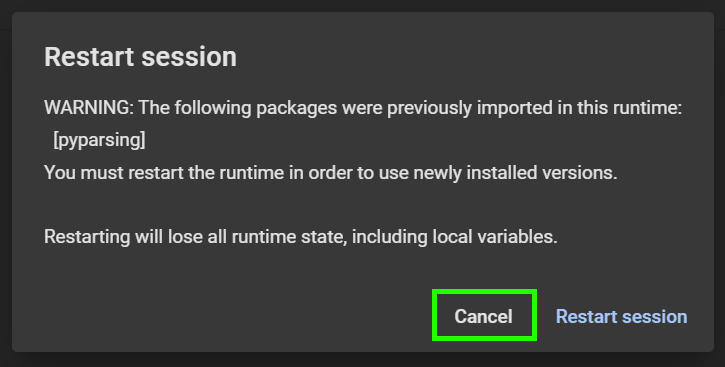
- このようなウィンドウが表示された場合は、「Cancel」をクリックしてください
セクション1.1
- セクションを展開し、最初のコードブロックを実行して、tfrecord.zipファイルへのGoogle Driveリンクを入力します。Google Driveでtfrecord.zipが「リンクを知っている全員」にアクセス可能になっていることを確認してください
セクション2
- 2つのコードブロックを実行して、tfrecord.zipを解凍し解析します
セクション3
- セクション3のすべてのコードブロックを実行して、トレーニングの準備をします
セクション4
-
セクション4のすべてのコードブロックを実行して、トレーニングを開始します。
-
トレーニングスクリプトの実行中、ファイルペインとtensorboardを更新して進捗を監視できます。2000ステップごとに「training_progress」フォルダに新しいチェックポイントが表示されます。
-
トレーニングは40000ステップで自動的に停止しますが、このセクションの最後のコードブロックの停止ボタンでいつでも停止できます。チェックポイントが利用可能であれば、量子化とコンパイルに進むことができます。
セクション5 - 7
- セクション5のすべてのコードブロックを実行して、ラベルファイルを生成し、モデルを互換性のあるFlatBuffer形式に変換します
- セクション6のすべてのコードブロックを実行して、INT8 / 8bit推論用にモデルを量子化します
- セクション7のすべてのコードブロックを実行して、Google CoralとLimelight用にモデルを準備します。最後のコードブロックには時間がかかり、トレーニング済みモデルが.zipファイルとしてダウンロードされます。
Limelightへのアップロード
- Colabセッションからのアーカイブを解凍します。
- FTCチーム - Limelight3Aをお持ちの場合は、8bit tfliteモデルとlabels.txtをアップロードしてください。ランタイムエンジンを「coral」から「cpu」に変更する必要があります
- FRCチーム - Google Coralをお持ちの場合は、limelight_neural_detector_coral.tfliteとlabels.txtファイルをLimelightにアップロードしてください。